
Objectivism on Substack
Analysis by Data Visualization

Which substacks know that A is A? As a new writer on Substack, I was curious about which other Objectivist blogs the platform has and what they're writing about. Some great publications are writing about Objectivism on Substack. A quick data visualization and analysis seemed in order.
The first step in any such project is gathering data. To get data on active substacks, several keyword searches were conducted with the “publications” filter. URLs were extracted from the search results of the following keywords:
Atlas Shrugged
Ayn Rand
Leonard Peikoff
Objectivism
Objectivist
Several more searches were conducted on tangentially related words with higher false positive rates, such as "libertarian", but set aside those results for future use. Next, I wrote an R language script to pull RSS data from the retrieved blogs. This pulled substantial metadata, most usefully the blog and post titles and descriptions. The RSS feeds only provided twenty results per feed, so they are not a complete representation of the blogs in question, but they were enough data to describe those I found.
The initial list included 106 feeds, which I then further filtered to confirm that terms of interest were used in the "item description" field, a snippet from the content of notes and posts. Of the remaining blogs, I did a quick review of each just to make sure they were on topic, removing those that were unrelated or only wrote one or two critique articles. This process distilled the results down to 14 blogs that were used for the data visualization. The RSS data did not reveal any “success metrics” (followers, total articles, etc.) and the exact sorting criteria of the substack.com and RSS search APIs remain opaque, thus they are presented in alphabetical order below.
Note: Depending on how a Substack has been configured, it may show a title or owner’s name above.
There are undoubtedly many more that weren't revealed in my surface-level scrape of search results.
The process of text mining involves removing uninteresting words or word parts. We call these uninteresting word parts "stop words" and they include things like "and", "if", "the", and, in this case, "substack", "article", and "blog". I say 'word parts' because oftentimes the suffixes of words like "ing" or "'s" can mask commonalities between terms and are therefore removed and disregarded through a process called "stemming". The stemmed word parts are called "grams" and are highly related to the LLM concept of a "token". I analyzed these grams individually (1-grams) and in sequential (bi-grams) and non-sequential (skip-grams) pairs.
Wordclouds are one of the go-to visualizations for getting a quick impression of what's being discussed across a large number of documents. Let's have a look at some. In the wordclouds below, the size of the word is determined by its relative frequency.
Our 1-gram wordcloud:

Skip-grams allow the analyst to find related words that may have a flexible number of words between the first and latter terms, like using the "*" wildcard in a double-quoted Google search term (i.e., "individual * rights"). However, the patterns revealed in our data with skip-grams mostly just reflected the same pairings I saw with bi-grams, which consider only adjacent words. Here are the bi-gram and skip-gram wordclouds for this data set.

Bi-grams are especially useful for catching references to individuals. References to Ayn Rand dominated all versions of the results, however, I was able to notice about a half dozen substacks referencing Donald Trump and several articles discussing the Canadian former politician Jagmeet Singh.

Bi-grams and skip-grams were also useful for noticing references to recent and upcoming events, such as a meeting of The Ayn Rand Society, which is a part of the American Philosophical Association and of course, the official annual Objectivist conference, OCON.
Treemap diagrams show how terms correspond to publications. The algorithm attempts to layer words on top of the substacks that those terms were found in, using color to help make the groupings clearer. Parts of the blogs' titles are sometimes obscured by the words layered on top of them. The size of the rectangles tell us about the frequency of the term in my data set.
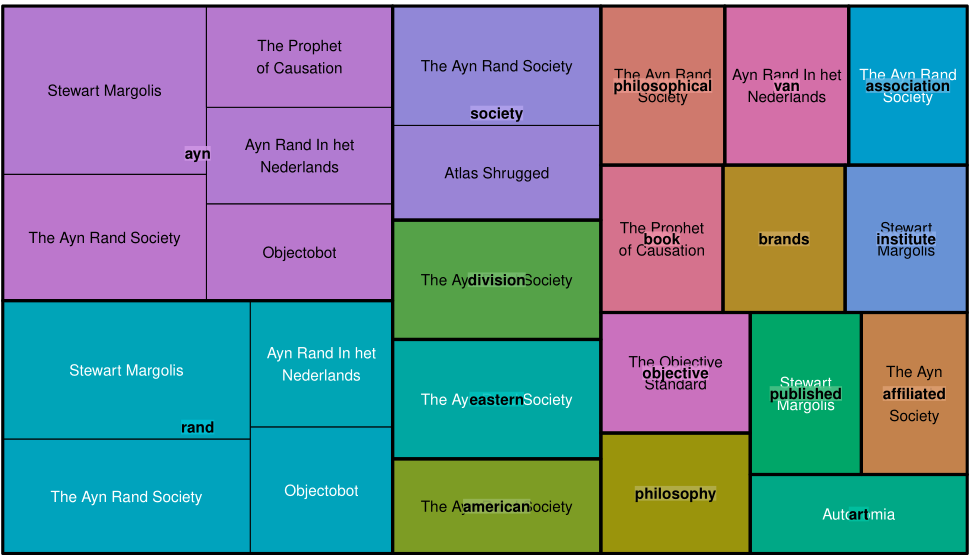
As always, the code used in this article is freely available on the Poso Press GitHub.
Thanks for adding my non-fiction writing, Jason. I also have a story podcast for my fiction, as I think you know. I appreciate the inclusion. It’s good to know about your thinking and methodology. Wishing you the best of luck and joy with your new endeavor. Cheers.
I think I'll do a follow-up to this soon(-ish) now that I've learned more about the Objectivist and libertarian landscape on Substack.